ヤコビ法の並列計算
ヤコビ法では,以下の行列方程式を,
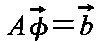
対角成分Dと上,下三角成分U,Lに分解して次のように繰り返し計算を行う.
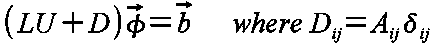
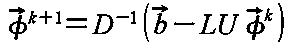
計算上は式を整理して,残差ベクトルを以下のように定義し,
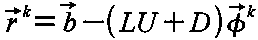
次の二つのベクトルを更新し,残差ベクトルのノルムが規定値を下回るまで繰り返す.
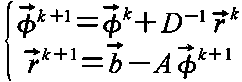
とりあえず,並列化していないプログラムはこんな感じ.ただし,計算の都合上NUMBEROFDIMENSIONSは
配列の上限値で,numberOfDimensionが問題の次元とする.
------------------------------------------------------------------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <sys/time.h>
#define NUMBEROFDIMENSIONS 500
int main(int argc, char* argv[])
{
double matrix[NUMBEROFDIMENSIONS][NUMBEROFDIMENSIONS];
double solution[NUMBEROFDIMENSIONS], solution_previous[NUMBEROFDIMENSIONS];
double sourceTerm[NUMBEROFDIMENSIONS];
int numberOfDimension = NUMBEROFDIMENSIONS / 2, i, j, iter;
double residual[NUMBEROFDIMENSIONS], error = 0.0;
FILE *fp;
struct timeval startTime, endTime;
struct timezone myTimeZone;
gettimeofday(&startTime, &myTimeZone);
printf("num dim: %d\n", numberOfDimension);
for(i = 0; i < NUMBEROFDIMENSIONS; i ++)
{
for(j = 0; j < NUMBEROFDIMENSIONS; j ++)
{
matrix[i][j] = 0.0;
}
}
// Set Matrix Coeff.
for(i = 0; i < numberOfDimension; i ++)
{
for(j = 0; j < numberOfDimension; j ++)
{
if(i == j)
matrix[i][j] = 1.0;
else if(j == i - 1)
matrix[i][j] = - 0.5;
else if(j == i + 1 && i != 0)
matrix[i][j] = - 0.5;
else
matrix[i][j] = 0.0;
}
}
matrix[numberOfDimension - 1][numberOfDimension - 2] = -1.0;
// Initialize Source Term
for(i = 0; i < NUMBEROFDIMENSIONS; i ++)
{
sourceTerm[i] = 0.0;
}
// Set Source Term
sourceTerm[0] = 1.0;
sourceTerm[1] = 1.0;
for(i = 0; i < numberOfDimension; i ++) solution[i] = 0.0;
for(i = 0; i < numberOfDimension; i ++)
{
residual[i] = sourceTerm[i];
for(j = 0; j < numberOfDimension; j ++)
{
residual[i] -= matrix[i][j] * solution[j];
}
}
for(iter = 0; iter < 5000; iter ++)
{
for(i = 0; i < numberOfDimension; i ++) solution_previous[i] = solution[i];
for(i = 0; i < numberOfDimension; i ++)
{
solution[i] = solution_previous[i] + residual[i] / (matrix[i][i] + 1.0e-200);
}
for(i = 0; i < numberOfDimension; i ++)
{
residual[i] = sourceTerm[i];
for(j = 0; j < numberOfDimension; j ++)
{
residual[i] -= matrix[i][j] * solution[j];
}
}
error = 0.0;
for(i = 0; i < numberOfDimension; i ++) error += residual[i] * residual[i];
}
gettimeofday(&endTime, &myTimeZone);
printf("error=%e\n", error);
fp = fopen("solution.txt", "w");
fprintf(fp, "err= %e\n");
for(i = 0; i < numberOfDimension; i ++) fprintf(fp, "%f\n", solution[i]);
fprintf(fp, "calculation time %f sec.\n", endTime.tv_sec - startTime.tv_sec + (endTime.tv_usec - startTime.tv_usec) / 1.e6);
printf("calculation time %f sec.\n", endTime.tv_sec - startTime.tv_sec + (endTime.tv_usec - startTime.tv_usec) / 1.e6);
fclose(fp);
}
------------------------------------------------------------------------------------------------------------------
これを一般的に並列で動かすことを考える.このような問題では,行列計算を行ごとに分けて行える.すなわちforループのi
によって繰り返されている計算がそれに当たる.そこで,例えば各プロセスに次のように行を割り当てる.
まず総プロセス数(並列度)をnum_procとし,numberOfDimension_local = numberOfDimension / num_procs + 1
によって,1プロセスあたりの担当する行を均等に割り振る.ただし,最後のプロセスだけは中途半端になることもある.
| proc# |
開始行 |
終了行 |
| 0 |
0 |
numberOfDimension_local - 1 |
| 1 |
1 * numberOfDimension_local |
2 * numberOfDimension_local - 1 |
| 2 |
2 * numberOfDimension_local |
3 * numberOfDimension_local - 1 |
| ... |
| n |
n * numberOfDimension_local |
(n + 1) * numberOfDimension_local - 1 |
| ... |
| num_procs - 2 |
(num_procs - 2)* numberOfDimension_local |
(num_procs - 1) * numberOfDimension_local - 1 |
| num_procs - 1 |
(num_procs - 1)* numberOfDimension_local |
numberOfDimension - 1 |
今回の並列化では,簡単のため全プロセスが全ての係数行列を持ち,解ベクトルも全次元持つとする.
そこで,各プロセスごとにインデックスの始めと終わり+1を,変数iBegin, iEndとして持つこととする.
iBegin, iEndは各プロセスごとに次のように計算する.my_procは自分のランク(プロセス番号)である.
iBegin = my_proc * numberOfDimension_local;
iEnd = iBegin + numberOfDimension_local;
ただし,iEndがnumberOfDimensionを超えないようにする.とりあえず,確認のため各プロセスのiBegin, iEndを計算して
表示するだけのMPIプログラムを作成してみる.
------------------------------------------------------------------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <mpi.h>
#include <sys/time.h>
#define NUMBEROFDIMENSIONS 500
#define ROOTPROC 0
int main(int argc, char* argv[])
{
double matrix[NUMBEROFDIMENSIONS][NUMBEROFDIMENSIONS];
double solution[NUMBEROFDIMENSIONS], solution_previous[NUMBEROFDIMENSIONS];
double sourceTerm[NUMBEROFDIMENSIONS];
int numberOfDimension = NUMBEROFDIMENSIONS / 2, i, j, iter;
double residual[NUMBEROFDIMENSIONS], error = 0.0, totalError;
FILE *fp;
int num_procs;
int my_proc;
int iBegin, iEnd, numberOfDimension_local;
int iError;
struct timeval startTime, endTime;
struct timezone myTimeZone;
gettimeofday(&startTime, &myTimeZone);
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &my_proc);
if(my_proc == ROOTPROC) printf("num dim: %d\n", numberOfDimension);
numberOfDimension_local = numberOfDimension / num_procs + 1;
if(numberOfDimension_local < 2)
{
printf("Too Large num_procs\n");
return -1;
}
iBegin = my_proc * numberOfDimension_local;
iEnd = iBegin + numberOfDimension_local;
if(iEnd > numberOfDimension) iEnd = numberOfDimension;
printf("proc %d, iBegin: %d, iEnd: %d\n", my_proc, iBegin, iEnd);
MPI_Finalize();
return 0;
}
------------------------------------------------------------------------------------------------------------------
コンパイルは,mpicc mpitest.c -o mpitestなどとすればよい.ccでなくmpiccを使うこと.
実行は,まずmpd &を実行しデーモンを立ち上げる.mpiexec_original -np 2 ./mpitestなどとする.
なぜmpiexecではなくmpiexec_originalかは第0回の資料の最後を参照.また,.mpd.confが各ユーザの
ホームディレクトリに配置され,内容がsecretword=[secretword]で,パーミッションをchmod 600 .mpd.conf
と変更しておかないと,mpdが動かない.(第0回の資料を参照)
これを実行すると次のように表示され,各プロセスに正しく割り当てられていることが確認できる.
$ mpiexec_original -np 5 ./test
num dim: 250
proc 0, iBegin: 0, iEnd: 51
proc 1, iBegin: 51, iEnd: 102
proc 2, iBegin: 102, iEnd: 153
proc 4, iBegin: 204, iEnd: 250
proc 3, iBegin: 153, iEnd: 204
$
このようにiBeginとiEndを求めておけば,
for(i = 0; i < numberOfDimension; i ++)の部分を
for(i = iBegin; i < iEnd; i ++)と書き換えるだけで並列化できる.
また,計算には前ステップの解ベクトルが必要となるためMPIによる通信が必要となってくる.すなわちsolution[j]を含む
計算があるため.対して残差ベクトルはresidual[i]のみしか現れないので,通信は不要である.通常の流体解析などでは,
必要になる行列方程式は疎行列である.そこで,疎行列などに特化した並列化を行うわけで,隣り合った領域を担当する
プロセス同士のみで解などを交換すればよい.しかしながら,今回の計算では一般的な行列を解くため,(と簡便性のため)全プロセスが
各イタレーション終了後に解ベクトルをそろえる設計とする.(ただし非常に効率が悪い)
そのような機能を実現する関数として,MPI_GatherとMPI_Bcastという関数がある.それぞれ,ルートプロセス(ランク0)
に配列の値を集める,ルートプロセスから各プロセスに配列を配信する,といった機能がある.また,残差のノルムを計算する
場合,各プロセスの部分残差のノルムの二乗を足し合わせる必要があるが,MPI_Reduceという関数が便利である.
以下にソースコードを示す.
------------------------------------------------------------------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <mpi.h>
#include <sys/time.h>
#define NUMBEROFDIMENSIONS 500
#define ROOTPROC 0
int main(int argc, char* argv[])
{
double matrix[NUMBEROFDIMENSIONS][NUMBEROFDIMENSIONS];
double solution[NUMBEROFDIMENSIONS], solution_previous[NUMBEROFDIMENSIONS];
double sourceTerm[NUMBEROFDIMENSIONS];
int numberOfDimension = NUMBEROFDIMENSIONS / 2, i, j, iter;
double residual[NUMBEROFDIMENSIONS], error = 0.0, totalError;
FILE *fp;
int num_procs;
int my_proc;
int iBegin, iEnd, numberOfDimension_local;
int iError;
struct timeval startTime, endTime;
struct timezone myTimeZone;
gettimeofday(&startTime, &myTimeZone);
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &my_proc);
if(my_proc == ROOTPROC) printf("num dim: %d\n", numberOfDimension);
numberOfDimension_local = numberOfDimension / num_procs + 1;
if(numberOfDimension_local < 2)
{
printf("Too Large num_procs\n");
return -1;
}
iBegin = my_proc * numberOfDimension_local;
iEnd = iBegin + numberOfDimension_local;
if(iEnd > numberOfDimension) iEnd = numberOfDimension;
// Initialize Matix Coeff.
for(i = 0; i < NUMBEROFDIMENSIONS; i ++)
{
for(j = 0; j < NUMBEROFDIMENSIONS; j ++)
{
matrix[i][j] = 0.0;
}
}
// Set Matrix Coeff.
for(i = 0; i < numberOfDimension; i ++)
{
for(j = 0; j < numberOfDimension; j ++)
{
if(i == j)
matrix[i][j] = 1.0;
else if(j == i - 1)
matrix[i][j] = - 0.5;
else if(j == i + 1 && i != 0)
matrix[i][j] = - 0.5;
else
matrix[i][j] = 0.0;
}
}
matrix[numberOfDimension - 1][numberOfDimension - 2] = -1.0;
// Initialize Source Term
for(i = 0; i < NUMBEROFDIMENSIONS; i ++)
{
sourceTerm[i] = 0.0;
}
// Set Source Term
sourceTerm[0] = 1.0;
sourceTerm[1] = 1.0;
// Paralle Start
for(i = iBegin; i < iEnd; i ++) solution[i] = 0.0;
MPI_Gather(&solution[iBegin], numberOfDimension_local, MPI_DOUBLE,
&solution[0], numberOfDimension_local, MPI_DOUBLE,
ROOTPROC, MPI_COMM_WORLD);
MPI_Bcast(&solution[0], numberOfDimension, MPI_DOUBLE, ROOTPROC, MPI_COMM_WORLD);
for(i = iBegin; i < iEnd; i ++)
{
residual[i] = sourceTerm[i];
for(j = 0; j < numberOfDimension; j ++)
{
residual[i] -= matrix[i][j] * solution[j];
}
}
for(iter = 0; iter < 5000; iter ++)
{
for(i = 0; i < numberOfDimension; i ++) solution_previous[i] = solution[i];
for(i = iBegin; i < iEnd; i ++)
{
solution[i] = solution_previous[i] + residual[i] / (matrix[i][i] + 1.0e-200);
}
MPI_Gather(&solution[iBegin], numberOfDimension_local, MPI_DOUBLE,
&solution[0], numberOfDimension_local, MPI_DOUBLE,
ROOTPROC, MPI_COMM_WORLD);
MPI_Bcast(&solution[0], numberOfDimension, MPI_DOUBLE, ROOTPROC, MPI_COMM_WORLD);
for(i = iBegin; i < iEnd; i ++)
{
residual[i] = sourceTerm[i];
for(j = 0; j < numberOfDimension; j ++)
{
residual[i] -= matrix[i][j] * solution[j];
}
}
error = 0.0;
for(i = iBegin; i < iEnd; i ++) error += residual[i] * residual[i];
MPI_Reduce(&error, &totalError, 1, MPI_DOUBLE, MPI_SUM, ROOTPROC, MPI_COMM_WORLD);
if(my_proc == ROOTPROC) printf("iter: %d, error: %e\n", iter, totalError);
}
gettimeofday(&endTime, &myTimeZone);
if(my_proc == ROOTPROC)
{
printf("error=%e\n", totalError);
fp = fopen("solution.txt", "w");
fprintf(fp, "err= %e\n", totalError);
for(i = 0; i < numberOfDimension; i ++) fprintf(fp, "%f\n", solution[i]);
fprintf(fp, "calculation time %f sec.\n", endTime.tv_sec - startTime.tv_sec + (endTime.tv_usec - startTime.tv_usec) / 1.e6);
printf("calculation time %f sec.\n", endTime.tv_sec - startTime.tv_sec + (endTime.tv_usec - startTime.tv_usec) / 1.e6);
fclose(fp);
}
MPI_Finalize();
}
------------------------------------------------------------------------------------------------------------------
※分かりさすさのため,MPI_GatherとMPI_Bcastを使って通信したが,MPI_Allgatherという関数を使えば一度に行える.
上記のプログラムのMPI_GathreとMPI_Bcastを,
MPI_Allgather(&solution[iBegin], numberOfDimension_local, MPI_DOUBLE, &solution[0], numberOfDimension_local, MPI_DOUBLE, MPI_COMM_WORLD);
とすればよい.
※今回の並列プログラムも簡単のため,かなり効率の悪いものとなっていると思われる.
おまけ
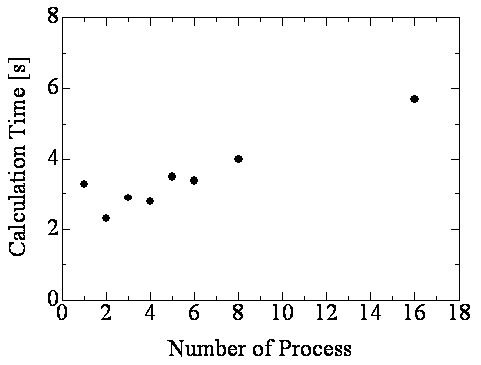
参考までに,並列化の効果を確認した結果を示しておく.
使用した計算機はデュアルコアのXeonである.かなり間抜けな並列化にもかかわらず,2並列ではそこそこ速くなった.(約1.5倍)
3, 4並列でもシングルよりは速い結果となっているが,5並列ではかえって遅くなる結果となる.そもそも2コアしか無いし,並列度を
上げると問題の大きさに対して通信コストが多くなるためと思われる.
by Jun ARAI, 2007.05.17