MPIでの並列計算
- 基本的にMPIは複数のプロセス間で,データ授受を実現するためだけのライブラリ.
- どのように並列化するかはユーザが明示的にプログラムする.
- 各プロセスは同じように実行されるが,プロセス番号(ランク)が通しでユニークに振られる.
- そこで,各プロセスは自分のランクを取得し,ランクによって異なる動作をするようなプログラムになる.
- 通常,ランク0のプロセスが親玉として動くようにプログラムする.
- 同時に動かすプロセス数(並列度)は,プログラム実行時に指定する.
実習
1+2+3+4+ ... +99+100を計算するプログラムを並列化する.
とりあえず,並列化していないプログラムはこんな感じ.
------------------------------------------------------------------------------------------------------------------
#include <stdio.h>
int main()
{
int result, i;
result = 0;
for(i = 0; i < 100; i ++)
{
result += i + 1;
}
printf("result=%d\n", result);
return 0;
}
------------------------------------------------------------------------------------------------------------------
これを2並列で動かすことを考える.例えば各プロセスの動作は次のようにする.
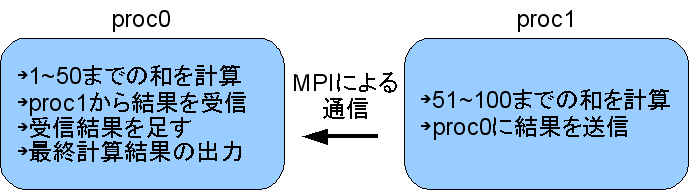
まず,MPIを初期化しプロセスの総数(つまり並列度)と,自分のランクを得るプログラムを作ってみる.
------------------------------------------------------------------------------------------------------------------
#include <stdio.h>
#include <mpi.h>
int main(int argc, char* argv[])
{
int num_procs;
int my_proc;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &my_proc);
if(my_proc == 0)
printf("I am process %d. Total number of processes: %d\n", my_proc, num_procs);
MPI_Finalize();
}
------------------------------------------------------------------------------------------------------------------
コンパイルは,mpicc mpitest.c -o mpitestなどとすればよい.ccでなくmpiccを使うこと.
実行は,まずmpd &を実行しデーモンを立ち上げる.mpiexec_original -np 2 ./mpitestなどとする.
なぜmpiexecではなくmpiexec_originalかは第0回の資料の最後を参照.また,.mpd.confが各ユーザの
ホームディレクトリに配置され,内容がsecretword=[secretword]で,パーミッションをchmod 600 .mpd.conf
と変更しておかないと,mpdが動かない.(第0回の資料を参照)
これによって,num_procsに総プロセス数が,my_procに自分のランクが格納される.
if(my_proc == 0)によってランク0のプロセスつまり親玉のみが画面表示を行っている.
MPI実行後はmpdallexitによってデーモンを全て終了させておくこと.
次にこのプログラムを改造し,2並列で100までカウントするプログラムを作る.
------------------------------------------------------------------------------------------------------------------
#include <stdio.h>
#include <mpi.h>
int main(int argc, char* argv[])
{
int num_procs;
int my_proc;
int i, n, result, result_local, result_recv, result_send;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &my_proc);
if(num_procs != 2)
{
printf("number of processes must be 2.\n");
MPI_Finalize();
return 0;
}
switch(my_proc)
{
case 0: n = 1; break;
case 1: n = 51; break;
}
result_local = 0;
for(i = n; i < n + 50; i ++) result_local += i;
result_send = result_local;
if(my_proc == 0)
MPI_Recv(&result_recv, 1, MPI_INT, 1, 0, MPI_COMM_WORLD, &status);
else
MPI_Send(&result_send, 1, MPI_INT, 0, 0, MPI_COMM_WORLD);
if(my_proc == 0)
{
result = result_local + result_recv;
printf("result = %d\n", result);
}
MPI_Finalize();
}
------------------------------------------------------------------------------------------------------------------
ここで,関数MPI_Recv, MPI_Sendによって通信を行っているわけだが,引数の型の詳細はSGIの資料に詳しい.
また,man MPI_Recvなどでマニュアルが見られる.簡単にそれぞれの引数の意味を説明しておく.
MPI_Recv
- 受信バッファ.つまり受信データを格納する変数へのポインタ.
- 受信データの個数.今回は1個のデータなので1とした.
- 受信データの型.ここでは整数型のMPI_INT.他の型はSGIの資料を参照.
- 送信元.送信側のランクを指定.
- タグ.送受信時の伝票のようなもので,送信受信で同じタグ(番号)をつけておく.
- コミュニケータ.MPI_COMM_WORLDを指定する.(特に変更する必要は無い)
- ステータス.通信のエラー番号などが格納される.
MPI_Send
- 送信バッファ.つまり送信データが格納されている変数へのポインタ.
- 送信データの個数.今回は1個のデータなので1とした.
- 送信データの型.ここでは整数型のMPI_INT.他の型はSGIの資料を参照.
- 送信先.送信先のランクを指定.
- タグ.送受信時の伝票のようなもので,送信受信で同じタグ(番号)をつけておく.
- コミュニケータ.MPI_COMM_WORLDを指定する.(特に変更する必要は無い)
※今回の並列プログラムは簡単のため,かなり効率の悪いものとなっていると思われる.MPIには送受信以外にも
親玉プロセスにデータを集めたりする関数や,合計を計算する関数なども用意されている.
TORQUE上での並列ジョブの実行
TORQUE上で並列ジョブを実行する際のスクリプト例(ファイル名をjob.shとする)を挙げておく.
#!/bin/sh
#PBS -N mpijoba
#PBS -j oe
#PBS -l nodes=1:ppn=2
#PBS -q default_que
cd $PBS_O_WORKDIR
mpiexec -np 2 ./mpicount
nodesは使用するノード数で,ppnはノードあたりのプロセス数.よってnodesとppnの積が最大の
プロセス数となるので,mpiexecの-np以上とする必要がある.npを省略すると最大プロセス数で実行される.
TORQUEでの実行では,mpdを立ち上げる必要はなく,qsub job.shとすれば自動で実行される.(第0回の資料参照)
by Jun ARAI, 2007.05.17